
Introduction: In our previous blog post, you have seen how to make data available directly from S3 bucket to Spice Engine for visualization using Quick Sight. In that case our data was already cleaned, normalized and processed and no need to be transformed. In this blog we will talk about using S3 bucket as a data lake however in the previous blog we used S3 as a data source. A data lake is a centralized repository that allows you to store all your structured and unstructured raw data which has not been cleaned and processed and can be stored as-is, there is no need to convert it to a predefined schema while Amazon S3 Data Source retrieves data from a file in Amazon S3.
AWS Glue has been used to finding the data and understanding the schema and data format as it reduces the time and effort that it takes to derive business insights quickly from an Amazon S3 data lake by discovering the structure and form of your data. AWS Glue automatically crawls your Amazon S3 data, identifies data formats, and then infer table schema's and store the associated metadata in the AWS Glue Catalog for use with other AWS analytic services like Athena.
Setting up the components:For setting up the components we will define a database, configure a crawler to explore data in an Amazon S3 bucket, create a table, transform the CSV file into Parquet, create a table for the Parquet data after that we will query the data with Amazon Athena and will create some visualization using Quick Sight.
1. Data Transformation using AWS Glue:
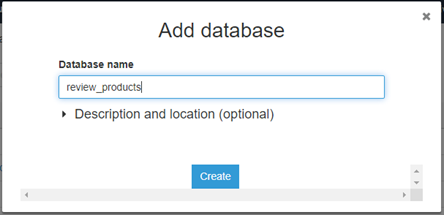
1.1 Fetching the Data: First, we need to choose AWS Glue service in the Analytics section of AWS Console Management and Create a database in there. For that in console we will choose Add database and write our database name and click on create.
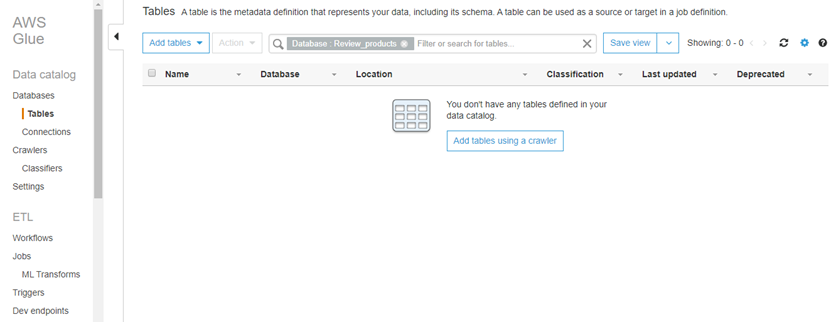
1.2 Add Tables: Choose Tables in navigation pane. A table is the metadata definition that represents your data, including its schema. A table can be used as a source or target in a job definition. We can add a table to the database review_products manually or by using a crawler. In this post we will use Crawler.
1.3 Add a Crawler: A crawler is a program that connects to a data store and progresses through a prioritized list of classifiers to determine the schema for your data. AWS Glue provides classifiers for common file types like CSV, JSON, Avro, and others.
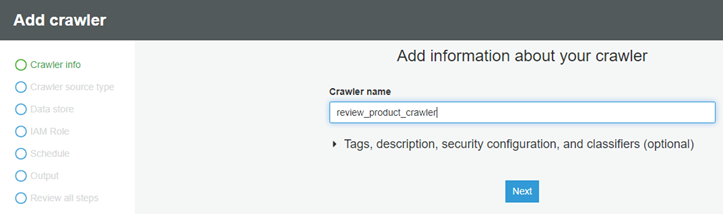
├ś Now we will choose Add crawler and specify the Crawler name ŌĆ£review_product_crawlerŌĆØ.
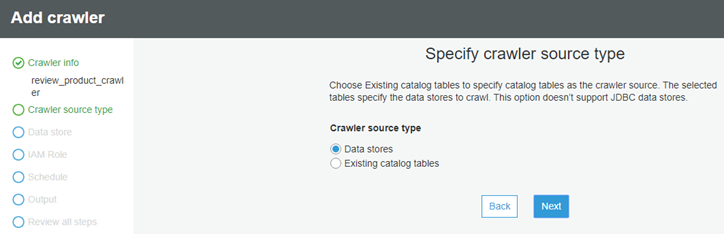
├ś we will specify crawler source type as Data stores and click on Next.
├ś We will choose a data store S3, For Crawl data in, choose Specified path in my account and for Include path, we will provide location of our raw csv files which are stored in our S3 bucket.
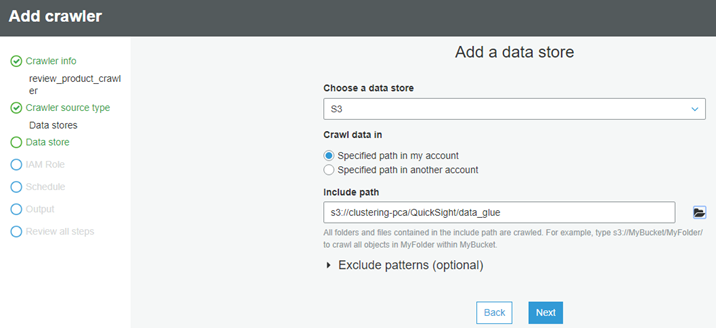
├ś For Add Another data store, we will choose No.

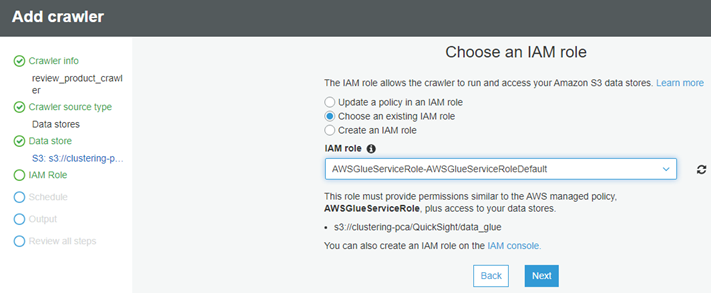
├ś We have option to choose an existing I AM role that AWS Glue can use for the crawler or we can create a new I AM role if we donŌĆÖt have any. For more information, please refer this link AWS Glue Developer Guide.
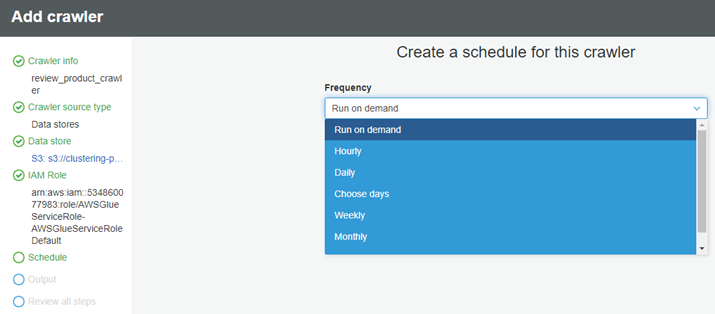
├ś For Frequency, Choose On demand. You can see here; we can choose preferable time to customize our crawler runs.
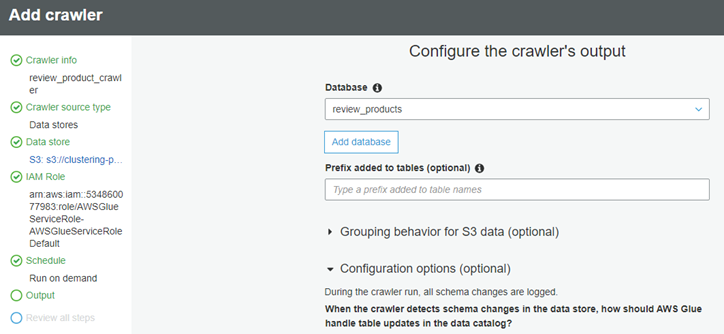
├ś We can configure the crawler output database and prefix: For Database, we will choose the database created earlier, ŌĆ£review_productsŌĆØ . Here we have not used any Prefix, but it can be added to tables (optional).
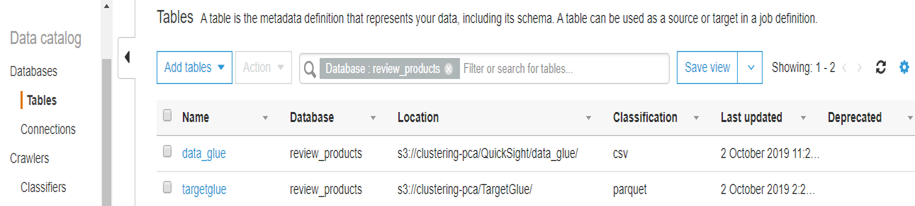
├ś Then we will choose Finish and Run it now. When the crawler is in ready state, we can see that one table has been added.
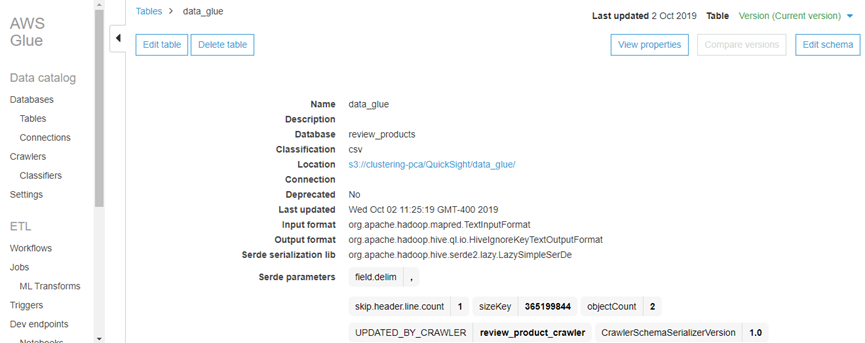
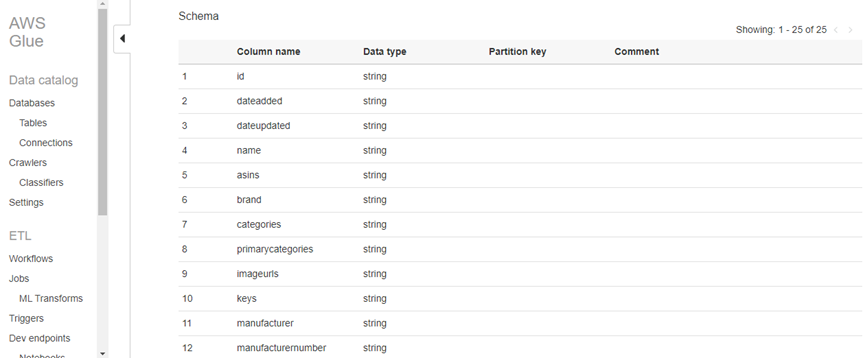
├ś Now we will Choose Tables in the left navigation pane, and then choose data_glue. This screen describes the table, including schema, properties, and other valuable information.
1.4 Transform the data from CSV to Parquet format: Now we will run a job to transform the data from CSV to Parquet. Parquet is a columnar format that is well suited for AWS analytics services like Amazon Athena and Amazon Redshift Spectrum.
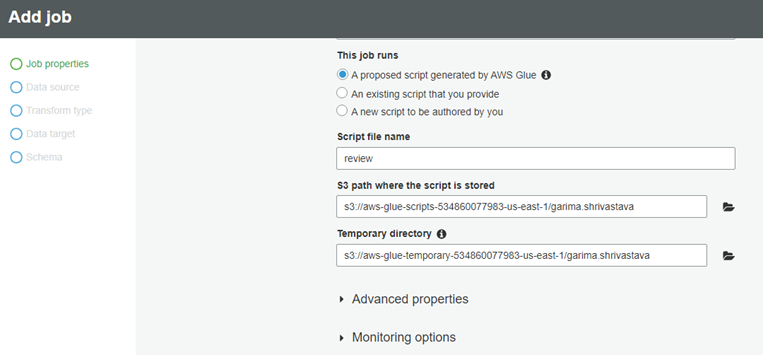
├ś Under ETL in the left navigation pane, choose Jobs, and then choose Add job.
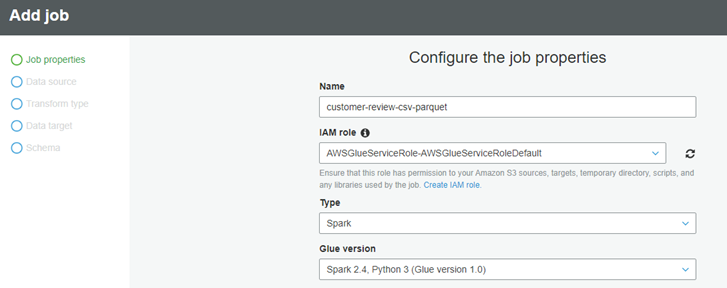
├ś For the Name, type customer-review-csv-parquet, For the I AM role, choose AWSGlueServiceRoleDefault and For This job runs, choose A proposed script generated by AWS Glue.
├ś Provide a unique Amazon S3 path to store the scripts and a unique Amazon S3 directory for a temporary directory.
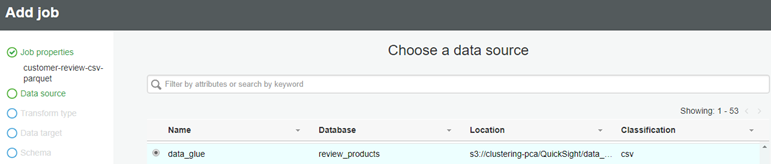
├ś Choose your folder name in S3 as the data source.
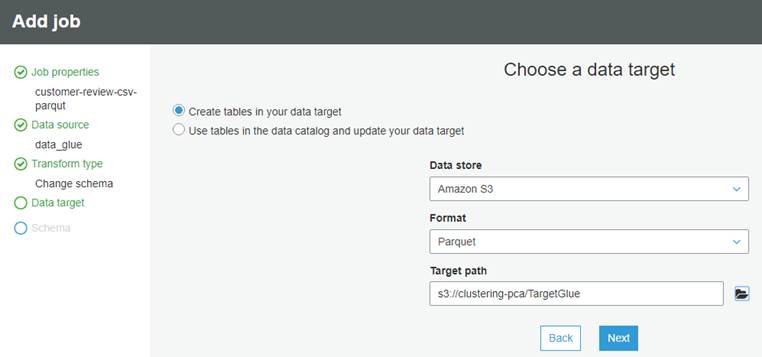
├ś Choose Create tables in your data target, Choose Amazon S3 as Data Store and Parquet as the format. Finally Choose a new location (a new prefix location without any existing objects) to store the results.
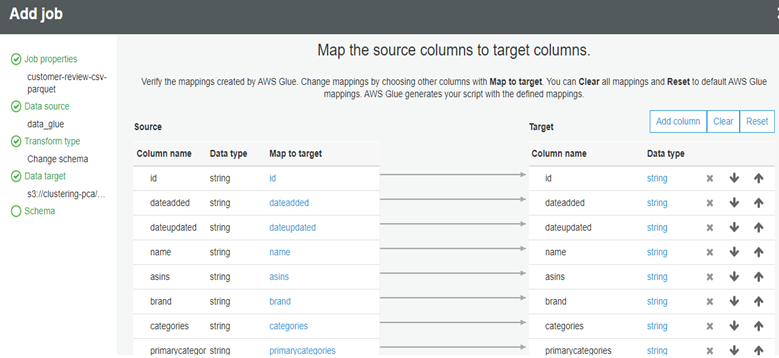
├ś Verify the schema mapping, save job and Edit the Script.
├ś Here in this screen you can see the complete view of the job. It allows you to edit, save, and run the job. AWS Glue created this script. However, if required, you can create your own.
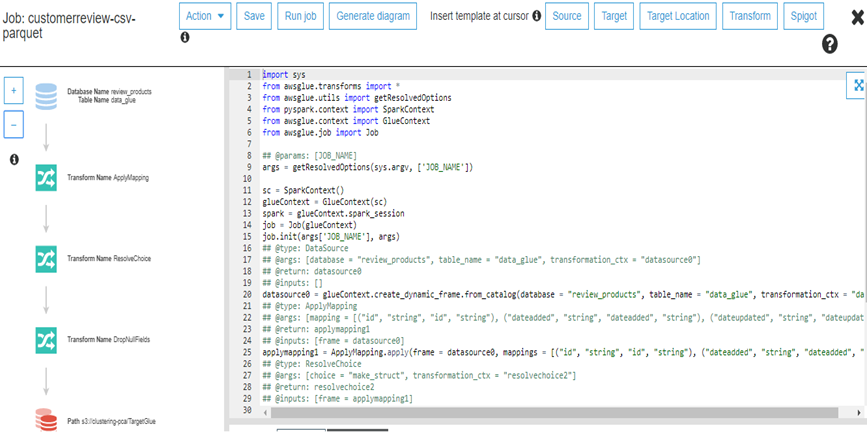
├ś Choose Save and Run the job. Now we can see There are two tables in our review_products database: a table for the raw CSV format and a table for the transformed Parquet format.
2. Query the data with Athena: Amazon Athena is an interactive query service that makes it easy to analyze data in Amazon S3 or in AWS Glue using standard SQL. To use AWS Glue with Athena, you must upgrade your Athena data catalog to the AWS Glue Data Catalog. Without the upgrade, tables and partitions created by AWS Glue cannot be queried with Athena. For more information on this please refer this link Athena Upgrade AWS Athena with AWS Glue .
This shows how you can interact with the data catalog either through Glue or the Athena.
├ś Go into the Athena Web Console.
├ś In the Query Editor, you can select your Glue Catalog database review_products which will display both tables data_glue and targetglue
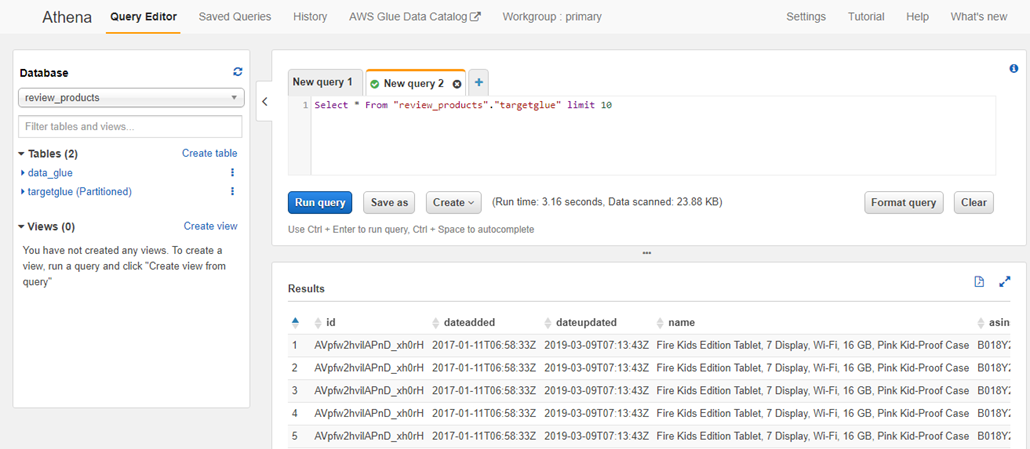
├ś You can query the data using standard SQL.
├ś Type Select * From ŌĆ£review_productsŌĆØ.ŌĆØtargetglueŌĆØ limit 10;
├ś Choose Run Query.
3. Fetching Data from Athena using Quick Sight: We need to create a data source in Spice and validate the connection with Athena.
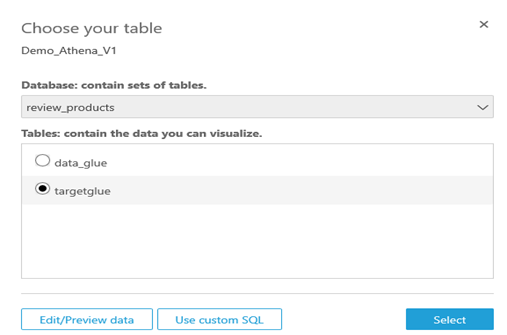
Now It will ask to choose the database stored in Athena and finally tables stored in that database.
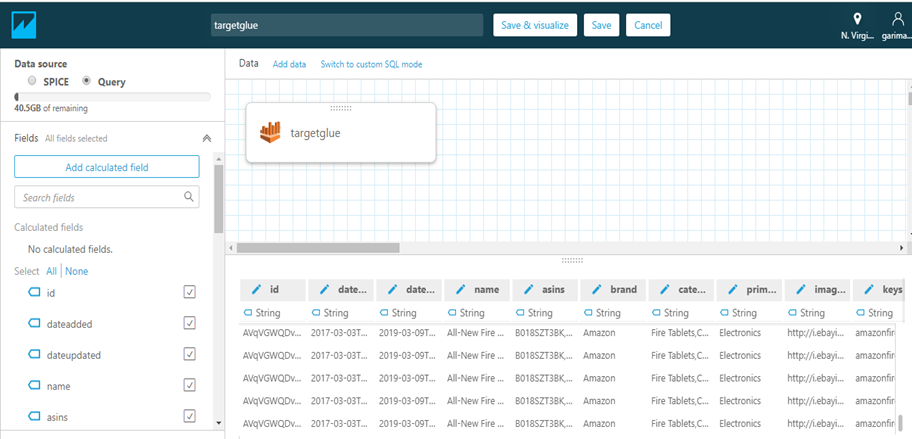
Once you choose Use custom SQL it will take you to the following page where you have option to add more tables from your database by choosing Add data and accomplish inbuilt join operations(Inner/Left/Right/Full) or you can Add a new join clause. We have option to switch to custom SQL mode to perform any sql queries in our data.
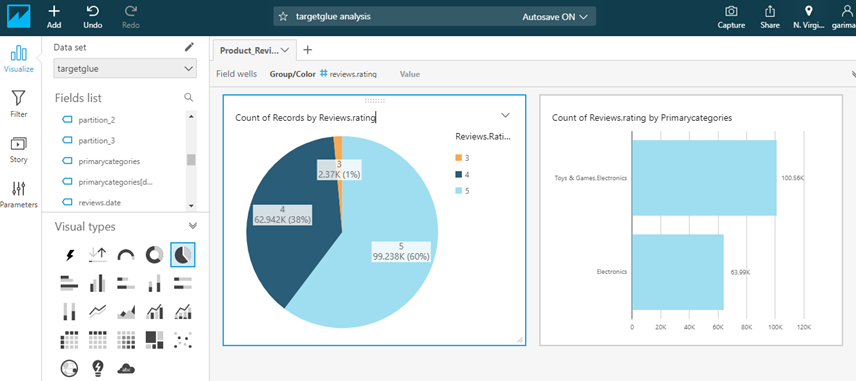
After you are done with all your modification click on Save & Visualize which will store your data into Spice and take you to this visualization screen where you can make charts and graph and your own custom Dashboard.
Summary: In this work our data has been stored in S3 bucket which is raw csv file and we want this data to be transform into parquet format using AWS Glue. So for that we have created an AWS Glue Crawler which will crawl all the data from S3 bucket and create a metadata catalog for it. Then we have added an AWS Glue ETL job which will transform our data from csv format to parquet format which is very convenient to be analyzed by Athena. Then we have used Amazon Athena to query our data through data catalog . At the end we have fetched the data from Athena to Spice Engine for visualization using Quick Sight. In this blog we have used these four AWS services AWS S3, Glue, Athena and Quick Sight which allow us to get the business insights faster.